
Aumente o desempenho de sua API com Redis e cache
Este texto introduz o uso de cache para aprimorar o desempenho de uma API. Apresenta um exemplo prático utilizando Node.js, Redis e MySQL, demonstrando a diferença de performance entre uma consulta simples sem cache e outra com cache.


Construir um sistema realmente não é uma tarefa simples. Já na fase inicial, há diversos requisitos que visam garantir performance e resiliência. Inclusive, não consigo pensar em um cenário onde estes dois itens não sejam primordiais para produzir um bom produto.
Quando uma parte do sistema apresenta lentidão, independente da razão, pode levar a uma redução no engajamento dos usuários. Inclusive, há estudos que abordam números relevantes ligados a desinstalação de apps devido lentidão.
53% of the time, visitors to mobile sites leave a page that takes more than three seconds to load
fonte: link
Há diversos recursos que podem ser utilizados para melhorarmos o tempo de resposta. Um deles, é o uso de cache. O princípio é simples, armazenamos dados que são frequentemente solicitados em um local que apresenta uma performance melhor do que o local da fonte da informação, por exemplo, podemos guardar alguns registros frequentemente solicitados do banco de dados e um banco de dados em memória. O acesso será muito mais rápido, reduzindo a latência.
Um pouco sobre o Redis
O Redis é uma ferramenta excelente para isso. É um banco de dados em memória de código aberto, reconhecido por sua rapidez, flexibilidade e escalabilidade em diversos casos de uso. Além do cache, o Redis tem aplicações em lock distribuído, dados de sessão, rate limit, entre outros.
Estratégia para uso de cache com Redis
Um cenário típico para o uso de cache são as consultas recorrentes cujo os dados não se alteram com tanta frequência.
Em um cenário típico, uma aplicação recebe a requisição, faz uma consulta em um banco de dados e então devolve o resultado na resposta da requisição. Quando estes dados são frequentemente requisitados e não mudam por um determinado período, pode ser uma boa estratégia armazenar estes dados, por exemplo, no Redis. Isto irá reduzir o processamento no banco de dados e também irá reduzir o tempo de resposta da sua aplicação.
A lógica é simples: ao receber uma requisição, verificamos se os dados estão em cache e os entregamos se estiverem. Caso contrário, consultamos o banco de dados, armazenamos os dados em cache e os entregamos.
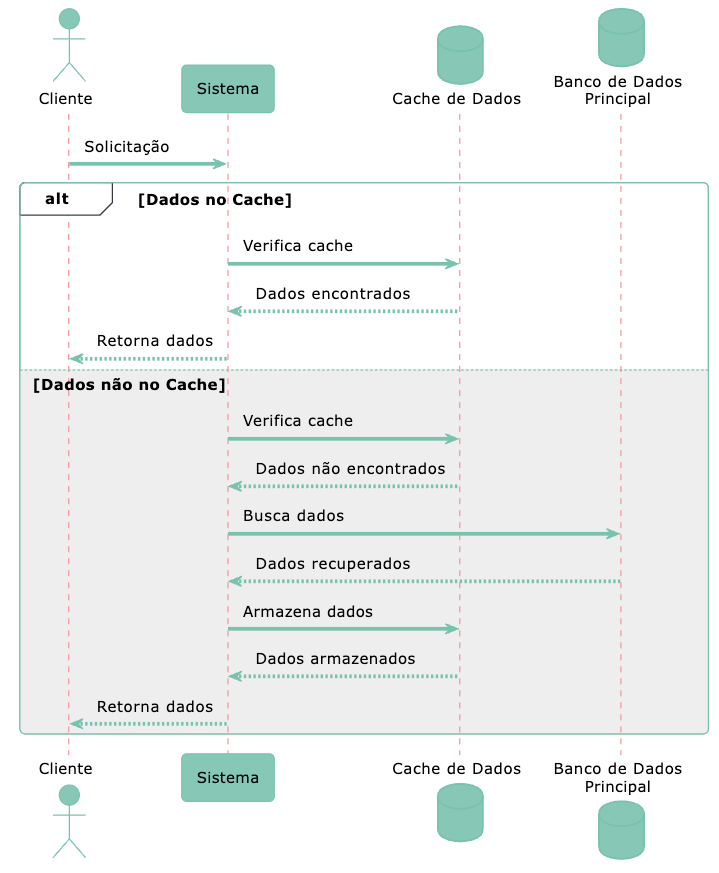
Para o cenário não ficar só no papel, vamos construí-lo e analisar o resultado.
Criando o cenário de estudo
Para criar o cenário de estudo do diagrama acima, são necessários três elementos: a aplicação, um banco de dados e o Redis. Vou desenvolver a aplicação em JavaScript com Node.js, usando o MySQL como banco de dados, embora outras opções também sejam viáveis.
Para o exemplo, primeiro é necessário instalar o Redis e o MySQL. No entanto, como quero um ambiente de estudo temporário, usarei o Docker para criar containers separados para o Redis e o MySQL, evitando complicações.
Se você não conhece o Docker, pense nele como um aplicativo que permite executar vários "computadores virtuais" isolados, cada um rodando programas específicos. Com o Docker, posso criar rapidamente containers para o Redis e o MySQL sem precisar instalar mais nada além do Docker.
https://docs.docker.com/get-started/overview/
Criando dois containers Docker: Redis e MySQL
Com o Docker instalado e em execução, basta rodar os seguintes comandos para criar containers com Redis e MySQL:
# Criando o container Redis:
docker run \
--name test-redis \
-d \
-p 3100:6379 \
redis
# Criando o container MySQL
# O MySQL irá guardar os arquivos no meu diretório
# /Users/marceloribasvismari/Docker-Volumes/test-mysql-redis
docker run \
--name test-mysql \
-d \
-p 3200:3306 \
-e MYSQL_USER=consolelog \
-e MYSQL_PASSWORD=consolelog \
-e MYSQL_ROOT_PASSWORD=consolelog \
-e MYSQL_DATABASE=test_mysql_redis \
-v /Users/marceloribasvismari/Docker-Volumes/test-mysql-redis:/var/lib/mysql \
mysqlComo o foco deste texto não é Docker, vou detalhar alguns parâmetros do comando acima:
docker runé o comando base do Docker que cria e executa um novo contêiner a partir de uma imagem Docker.p 3200:3306mapeia uma porta da máquina host (computador que está executando o Docker) para uma porta do contêiner. No caso3200é a porta da máquina host e3306é a porta do contêiner (porta padrão do MySQL).-v /Users/marceloribasvismari/Docker-Volumes/test-mysql-redis:/var/lib/mysqlmapeia um volume (diretório) da máquina host para um diretório no contêiner. No caso/Users/marceloribasvismari/Docker-Volumes/test-mysql-redisé o diretório no host e/var/lib/mysqlé o diretório no contêiner onde o MySQL armazena seus dados.- Os parâmetros
eindicam variáveis de ambiente dentro do container.
Após executar os comandos acima, serão criados dois containers. Para consultar esses containers, use o CLI do Docker:
docker container ls
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
5c28e33b46ad mysql "docker-entrypoint.s…" 6 seconds ago Up 5 seconds 33060/tcp, 0.0.0.0:3200->3306/tcp test-mysql
a2ec98f66eb9 redis "docker-entrypoint.s…" 3 minutes ago Up 3 minutes 0.0.0.0:3100->6379/tcp test-redisAgora que temos o Redis e o MySQL em execução, vamos:
- Estruturar o projeto em JavaScript.
- Criar um script chamado
carga-banco.jspara carregar dados no banco de dados. - Desenvolver o script
index-sem-redis.jspara retornar dados do MySQL em um endpoint. - Desenvolver o script
index-com-redis.jspara retornar dados do MySQL utilizando o Redis como cache para as consultas SQL.
Criando o projeto
Primeiro, é necessário iniciar o projeto e instalar as dependências. Escolha um diretório de sua preferência e execute os seguintes comandos:
# Cria o projeto
npm init -y
# Instala as dependências
npm i [email protected]
npm i [email protected]Efetuando uma carga no banco de dados
Para criar alguns registros no banco de dados, escrevi um pequeno script que cria uma tabela e inseri alguns registros.
Observação: Não tratei possíveis erros, pois este é apenas um script de estudo.
import mysql from "mysql2/promise";
(async () => {
const dbConnection = await mysql.createConnection({
host: "127.0.0.1",
port: 3200,
user: "consolelog",
password: "consolelog",
database: "test_mysql_redis",
});
await dbConnection.connect();
const createTableCommand = `CREATE TABLE IF NOT EXISTS dados_teste (
id INT PRIMARY KEY AUTO_INCREMENT,
nome VARCHAR(255) NOT NULL,
email VARCHAR(255) NOT NULL,
cidade VARCHAR(255) NOT NULL,
data_nascimento DATE NOT NULL
);`;
await dbConnection.query(createTableCommand);
for (let i = 0; i < 500; i++) {
const insertCommand = `INSERT INTO dados_teste (nome, email, cidade, data_nascimento)
VALUES ('Usuário ${i}', 'usuario${i}@example.com', 'Cidade ${i}', '1980-01-01');`;
await dbConnection.query(insertCommand);
}
console.log("Script finalizado");
process.exit(0);
})();
carga-banco.js
Após executar o script, node carga-banco.js, acessei o terminal do container para conferir se os registros realmente foram inseridos:
# Primeiro localize o id do container:
docker container ls --filter name=test-mysql
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
5c28e33b46ad mysql "docker-entrypoint.s…" 4 hours ago Up 13 minutes 33060/tcp, 0.0.0.0:3200->3306/tcp test-mysql
# Acessando o terminal do container
docker exec -it 5c28e33b46ad /bin/bash
# A partir daqui estamos "dentro" do container
bash-4.4# mysql -u consolelog -p
Enter password: <coloque a senha consolelog>
mysql> use test_mysql_redis;
mysql> select count(1) from dados_teste;
+----------+
| count(1) |
+----------+
| 500 |
+----------+
1 row in set (0.01 sec)Agora que temos alguns registros no banco de dados para utilizar no cenário de estudo, vamos para o próximo passo.
Criando a API que irá fornecer os dados
Por fim, criei dois arquivos para serem executados individualmente durante os testes.
import { createServer } from 'node:http';
import mysql from 'mysql2/promise';
(async () => {
const dbConnection = await mysql.createConnection({
host: '127.0.0.1',
port: 3200,
user: 'consolelog',
password: 'consolelog',
database: 'test_mysql_redis',
});
await dbConnection.connect();
const server = createServer(async (_, res) => {
try {
const [data] = await dbConnection.query(
'SELECT * FROM `dados_teste`',
);
const dataStringify = JSON.stringify(data);
res.writeHead(200, { 'Content-Type': 'application/json' });
res.end(dataStringify);
} catch (err) {
console.error(err);
res.writeHead(500);
res.end('Internal Server Error');
}
});
server.listen(3000, '127.0.0.1', () => {
console.log('Listening on 127.0.0.1:3000');
});
})();
index-sem-redis.js
import { createServer } from 'node:http';
import { createClient } from 'redis';
import mysql from 'mysql2/promise';
(async () => {
const dbConnection = await mysql.createConnection({
host: '127.0.0.1',
port: 3200,
user: 'consolelog',
password: 'consolelog',
database: 'test_mysql_redis',
});
await dbConnection.connect();
const redisClient = await createClient({
url: 'redis://localhost:3100',
}).connect();
const server = createServer(async (_, res) => {
try {
const cachedData = await redisClient.get('meus-dados');
if (cachedData) {
res.writeHead(200, { 'Content-Type': 'application/json' });
return res.end(cachedData);
}
const [data] = await dbConnection.query(
'SELECT * FROM `dados_teste`',
);
const dataStringify = JSON.stringify(data);
await redisClient.set('meus-dados', dataStringify);
res.writeHead(200, { 'Content-Type': 'application/json' });
res.end(dataStringify);
} catch (err) {
console.error(err);
res.writeHead(500);
res.end('Internal Server Error');
}
});
server.listen(3000, '127.0.0.1', () => {
console.log('Listening on 127.0.0.1:3000');
});
})();
index-com-redis.js
Observação: Não tratei possíveis erros, pois este é apenas um cenário de estudo.
O primeiro script não utiliza o Redis. Sempre que uma requisição é recebida, ele consulta o banco de dados diretamente e retorna os registros. Já o segundo script primeiro verifica se a informação está no Redis. Se estiver, ele retorna os dados diretamente do Redis. Caso contrário, ele consulta o banco de dados, armazena o resultado no Redis e, em seguida, retorna os dados.
Comparando a performance com e sem Cache com Redis
Para comparar o ganho no uso do cache, segui este procedimento:
- Executei o comando
node index-sem-redis.js. - Rodei o comando
autocannon localhost:3000três vezes, guardei os resultados para o scriptindex-sem-redis.jse na sequência interrompi sua execução. - Executei o comando
node index-com-redis.js. - Rodei o comando
autocannon localhost:3000três vezes e guardei os resultados para o scriptindex-com-redis.js.
Abaixo estão os resultados comparando os dois scripts: um utiliza o Redis para cachear os dados do banco de dados, enquanto o outro não. Sem o Redis, a capacidade ficava em torno de 1200 requisições por segundo. Com a adição do cache usando Redis, essa capacidade aumentou para cerca de 3800 requisições por segundo, resultando em um ganho de desempenho superior a 3 vezes.
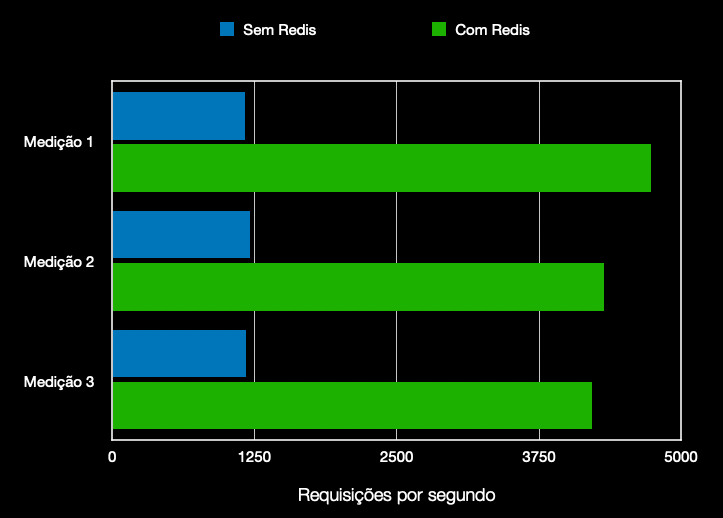
Observe que, com poucas alterações, podemos obter um ganho de desempenho bastante expressivo. Em contrapartida, tivemos que adicionar um pouco mais de código para fazer a gestão do cache.
Observação: Os testes foram realizados em um computador de trabalho, e os resultados podem variar em outros computadores/servidores. Embora um ganho de desempenho seja esperado, é importante medir esse ganho no seu próprio ambiente.
Considerações
O cenário de estudo abordado neste texto é apenas um caso simples onde o uso de cache pode trazer benefícios. Alguns cenários podem não ser adequados para o uso de cache. Essa análise dependerá de diversos fatores, como a complexidade da gestão do cache, a periodicidade da modificação da informação, o nível de consistência que seu requisito de negócio demanda, entre outros.
Além do Redis, há outros softwares como, por exemplo, o Memcached e o Apache Ignite. Portanto, se você está procurando alguma solução para cache, considere fazer uma comparação entre estas opções para determinar qual melhor se encaixa nos seus requisitos de negócio.
Outro ponto que não comentei é que o exemplo abordado neste texto segue um padrão de estratégia de leitura chamado Cache Aside. Existem outros padrões, como Read Through, Write Around, etc. Conforme você for se aprofundando no assunto, sugiro estudar mais sobre as diferentes estratégias de cache.
Links interessantes:
- Video falando sobre exemplos de uso do Redis: https://www.youtube.com/watch?v=a4yX7RUgTxI
- Explicação sobre a estratégia Cache Aside:
https://learn.microsoft.com/en-us/azure/architecture/patterns/cache-aside


